Project: Material Specs KB — RAG-Based Product Knowledge Assistant
Role: AI Content Architect & Technical Writer
Stack: Flowise, OpenAI API (text-embedding-3-small, GPT-4o-mini), Pinecone, Google Drive
About the project
Material Specs KB is a portfolio project demonstrating the design and deployment of a RAG-based AI knowledge assistant built on a library of 30 real manufacturer technical data sheets. The system allows any team member to query material properties—heat resistance, tensile strength, viscosity, thermal conductivity—by asking plain-language questions, rather than manually searching through PDF files.
The project was designed to mirror a common SME use case: a non-technical team that needs fast, accurate access to product specifications from an ever-growing library of supplier documents.
Challenge
Technical data sheets create a retrieval problem at scale. A team managing 30, 100, or 500 PDFs across multiple suppliers and material types cannot practically locate a specific property value by opening files manually. Standard keyword search fails on technical queries. Searching “thermal performance” will not surface a document that uses the term “thermal conductivity.”
Three constraints shaped the design:
- Accuracy: Answers had to be grounded exclusively in the source PDFs. No hallucination from general model training data. In a materials context, a wrong specification can mean a failed product or a liability issue.
- Maintainability: The system needed to be updatable without technical intervention. Adding a new data sheet should require nothing more than dropping a file into a folder.
- Accessibility: The interface needed to be usable by non-technical staff with no training overhead.
Strategic execution
1. Content audit and taxonomy design
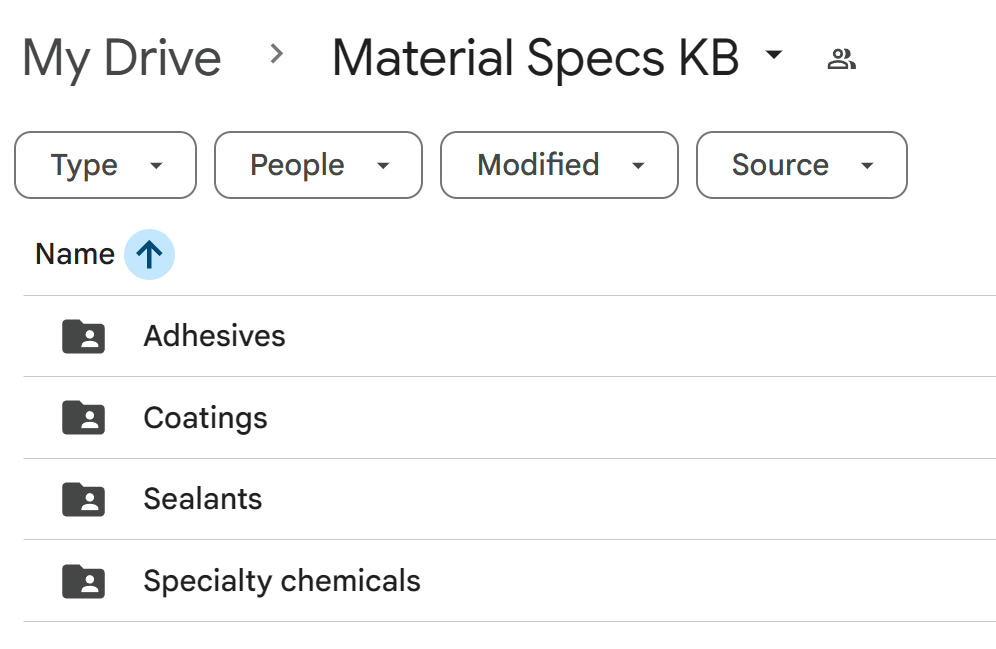
Before any technical build, the document library was audited to determine appropriate categorisation. Thirty technical data sheets from five manufacturers (Dow, Loctite, Sika, 3M, Momentive) were reviewed and sorted into four categories:
- Adhesives: bonding and fastening products (Loctite threadlockers, structural adhesives)
- Sealants: gap-filling and joint sealing products
- Coatings: surface-applied protective and waterproofing membranes
- Specialty Chemicals: additives, surfactants, coupling agents, and thermal interface materials
The taxonomy decision was deliberately kept broad, four categories across 30 PDFs, to ensure each folder was meaningfully populated. Overly granular folder structures with two or three files per category undermine both retrieval quality and the maintainability goal.
Key finding during audit: several Dow products (VORASURF 2904 surfactant, DOWSIL Z-6094 silane coupling agent, XIAMETER modifiers) did not fit standard adhesive/sealant/coating categories. Rather than forcing them into an ill-fitting bucket, a Specialty Chemicals category was created. This kind of content-first taxonomy decision is the difference between a knowledge base that stays organised over time and one that becomes inconsistent as new documents are added.
2. Knowledge architecture and ingestion
Documents were stored in a structured Google Drive folder (Material Specs KB) with subfolders by category. The folder is shared with a service credential, allowing the RAG pipeline to ingest directly from Drive without manual uploads.
Chunking strategy: 1,000-word chunks with 200-word overlap. Larger than a standard 500-word chunk to preserve the integrity of specification tables. Technical data sheets contain dense numerical data where splitting mid-table destroys retrieval accuracy. The 200-word overlap ensures that values appearing near chunk boundaries are captured in at least one retrievable segment.
Ingestion results: 30 PDFs processed into 130 vectors. Embedding cost: under $0.01.
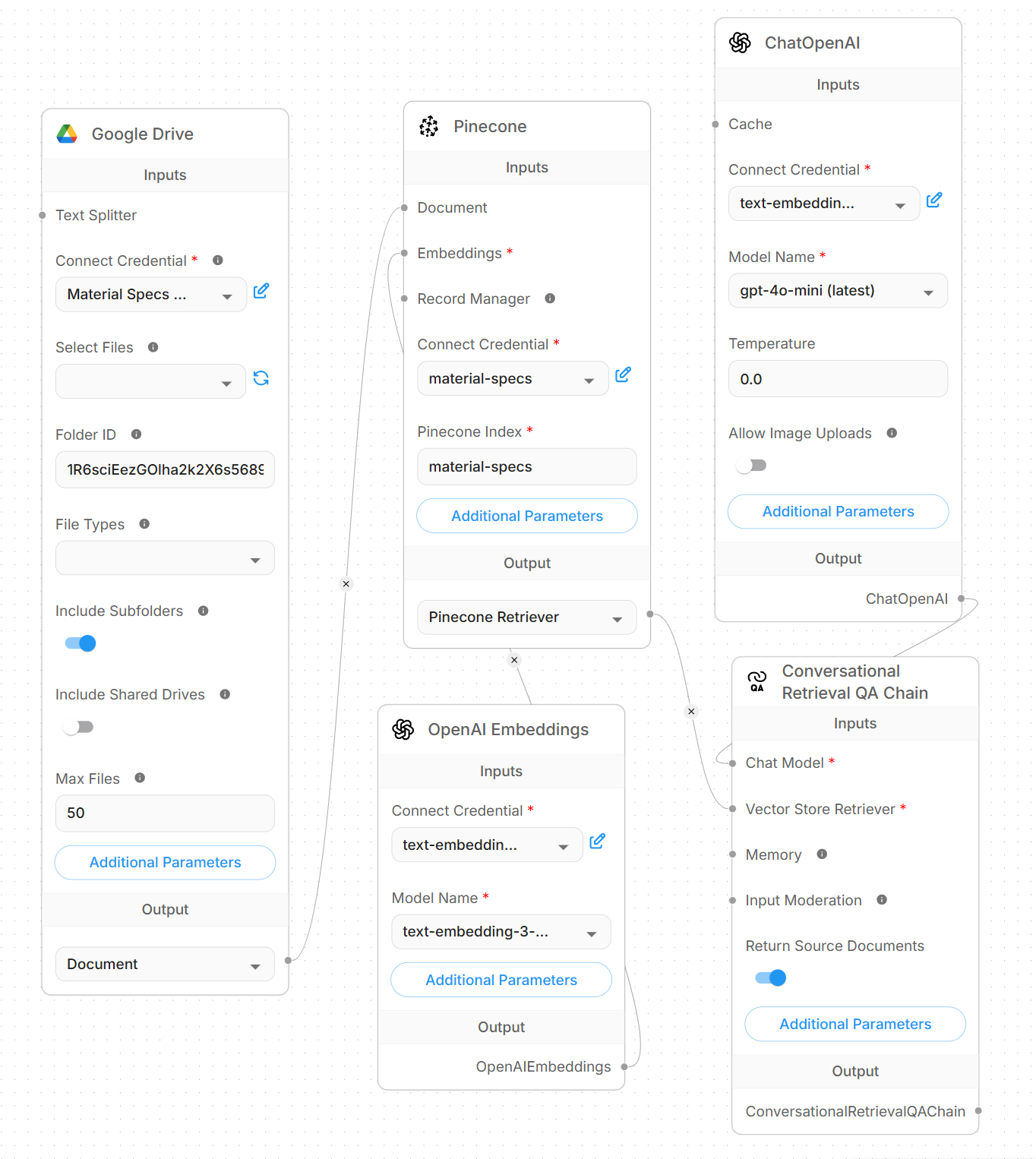
Google Drive (PDF Library)
↓ ingest
Document Parser
↓ chunk (1,000w / 200w overlap)
OpenAI Embeddings
↓ embed (text-embedding-3-small)
Pinecone Vector DB
↓ retrieve (cosine similarity)
Flowise Query Interface
↓ generate
GPT-4o-mini Response
3. Vector database and retrieval layer
Configured a Pinecone serverless index using cosine similarity and OpenAI’s text-embedding-3-small model (1,536 dimensions). At query time, the user’s question is embedded and matched semantically against the full corpus, surfacing relevant content regardless of exact keyword match.
This is the core advantage over standard document search: a query for “products that perform well at high temperatures” retrieves documents that discuss continuous service temperatures and thermal resistance, even if the phrase “high temperature” does not appear verbatim.
4. System prompt and generation rules
The system prompt enforces three behaviours:
- Answer only from retrieved document context and never from general model knowledge.
- Return specific numerical values where available.
- Acknowledge when information is not present in the knowledge base rather than guessing.
The third rule is critical for a technical specification use case. A system that confidently fabricates a tensile strength value is more dangerous than one that says “I don’t have that information.”
5. Deployment
Deployed as a no-code pipeline in Flowise Cloud, embedded as a chat interface accessible to any team member via browser. No installation, no training, no technical knowledge required to use or maintain.
Maintenance workflow for non-technical staff: add a new PDF to the relevant Google Drive subfolder → run a one-click re-index → new document is live in the knowledge base within minutes.
System performance
| Metric | Result |
|---|---|
| Documents indexed | 30 PDFs |
| Vectors stored | 130 |
| Manufacturers covered | 5 (Dow, Loctite, Sika, 3M, Momentive) |
| Material categories | 4 |
| Embedding cost | < $0.01 |
| Estimated monthly running cost | $55–$100 |
Stress test results
The system was tested against six query types to validate accuracy, retrieval breadth, and hallucination resistance.
Accuracy — specific numerical values
“What is the thermal conductivity of DOWSIL 340?” Answer: The thermal conductivity of DOWSIL™ 340 Heat Sink Compound is 0.39 btu/hr-ft-°F or 0.67 W/m-K.
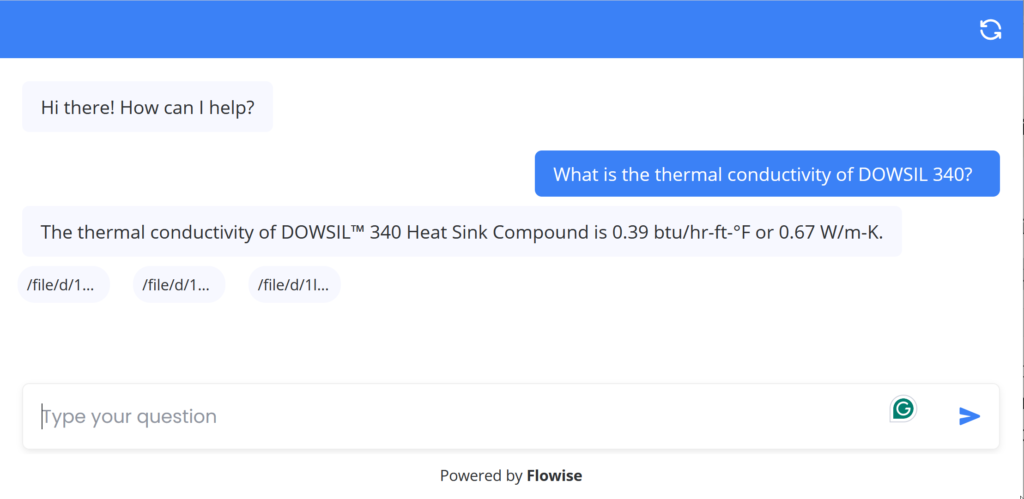
“What is the viscosity of DOWSIL 340?” Answer: The viscosity of DOWSIL™ 340 Heat Sink Compound is 542,000 cP (Pa-sec).
Both answers match the source PDF exactly. No approximation, no inference. Only direct retrieval of published specification values.
Cross-document retrieval
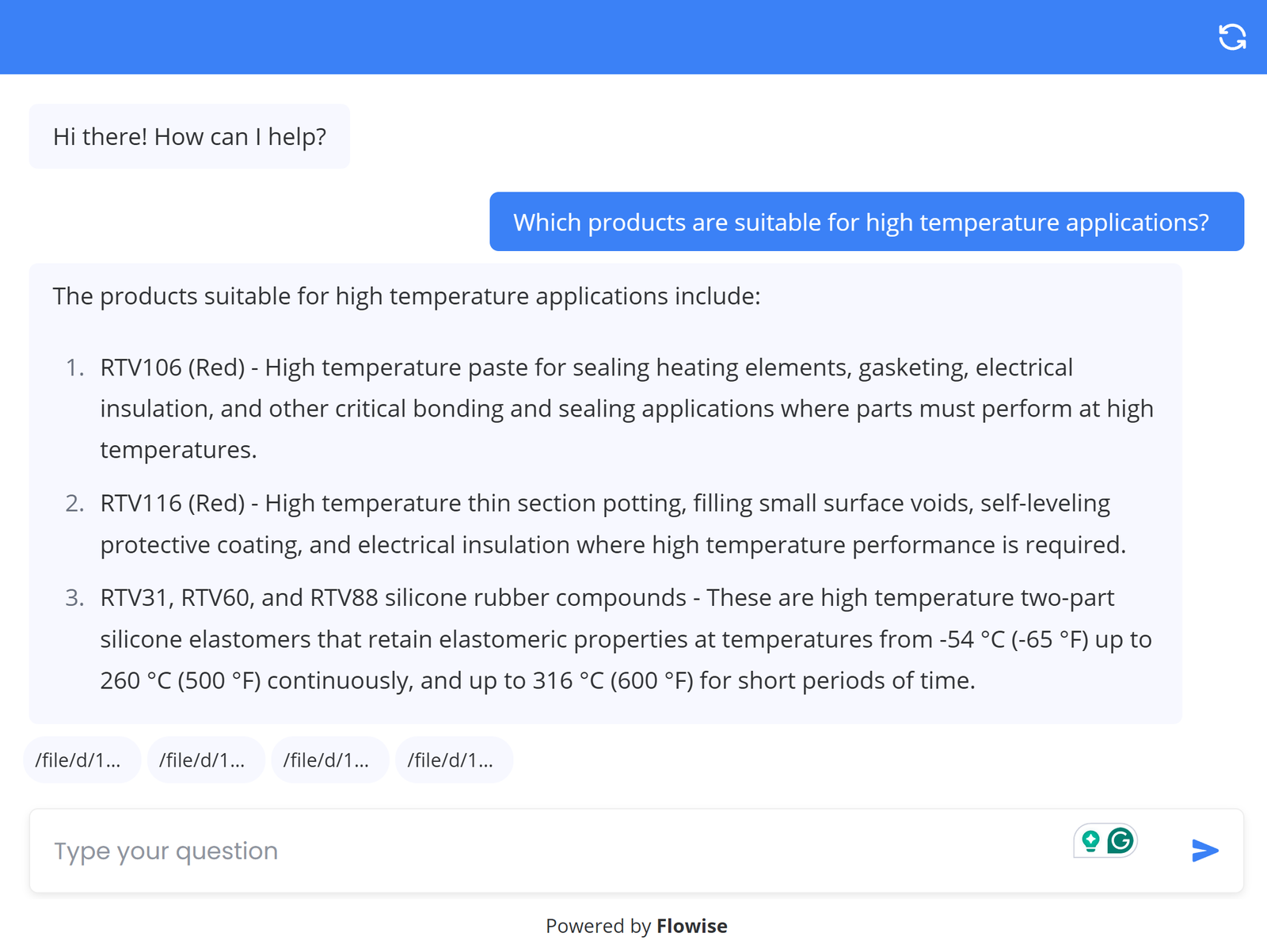
“Which products are suitable for high temperature applications?” Answer: The following products are suitable for high temperature applications:
- RTV106 (Red): High temperature paste for sealing heating elements, gasketing, and electrical insulation.
- RTV116 (Red): High temperature thin section potting, self-leveling protective coating, and electrical insulation.
- RTV31, RTV60, and RTV88: High temperature two-part silicone elastomers that retain elastomeric properties from -54°C (-65°F) up to 260°C (500°F) continuously, and up to 316°C (600°F) for short periods.
This response required retrieval across multiple PDFs from multiple categories — the single most valuable capability for a team managing a diverse product library.
Boundary and hallucination tests
“What is the price of Loctite 262?” Answer: Hmm, I’m not sure.
“What is the tensile strength of titanium?” Answer: Hmm, I’m not sure.
Price data does not appear in technical data sheets. Titanium is not in the document library. In both cases, the system correctly declined to answer rather than generating a plausible-sounding fabrication. This behaviour is non-negotiable for any system used to make materials or procurement decisions.
Client cost breakdown
For a small internal team (up to 15 users, up to 100 PDFs):
| Service | Purpose | Monthly cost |
|---|---|---|
| OpenAI API | Embeddings + chat responses | ~$20–40 |
| Pinecone | Vector index storage | Free tier (up to 2M vectors) |
| Flowise Cloud | Pipeline hosting and chat interface | $35 |
| Google Drive | Document storage | Existing subscription |
| Total | ~$55–75/month |
No developer retainer required for ongoing maintenance. The system is maintained by managing a Google Drive folder.
Interpretation
This project demonstrates that a no-code RAG pipeline can deliver production-quality knowledge retrieval for a non-technical SME team at a running cost under $100 per month.
The critical design decisions, content-first taxonomy, chunk sizing optimised for tabular data, strict grounding rules in the system prompt, are knowledge architecture decisions, not engineering decisions. They determine whether the system is accurate and maintainable over time. Getting them right at build time prevents the failure mode common to developer-built systems: a chatbot that works well for three months, then gradually degrades as the document library grows, and nobody knows how to maintain it.
The maintenance workflow for this system requires no technical knowledge. Any team member who can manage a folder can keep the knowledge base current.
Resources
- Live demo (suggested questions: Which products are suitable for high temperature applications? or What is the thermal conductivity of DOWSIL 340?)