Project: AdTech Knowledge Assistant, RAG-Based Wikipedia Corpus
Role: AI Content Architect and Technical Writer
Stack: Python, OpenAI API (text-embedding-3-small, GPT-4o-mini), Pinecone, Flask, Wikipedia API, Render, GitHub
About the project
The AdTech Knowledge Assistant is a portfolio project (programmatic advertising knowledge base) demonstrating the design and deployment of a RAG-based AI knowledge assistant built on a curated corpus of 24 Wikipedia articles covering programmatic advertising, digital marketing, and privacy regulation. Any user can ask plain-language questions about AdTech concepts and receive accurate, sourced answers grounded exclusively in the knowledge base.
The project was designed to mirror a real client use case: an AdTech team, agency, or publisher that needs fast, reliable answers to programmatic advertising questions without searching manually across multiple reference sources.
Challenge
Programmatic advertising is a complex, jargon-heavy discipline. New practitioners and non-technical stakeholders—marketers, account managers, sales teams—regularly need to understand concepts like real-time bidding, header bidding, data management platforms, and privacy regulations like GDPR and CCPA. Standard web search returns inconsistent, commercially biased results. A curated knowledge assistant grounded in authoritative content solves this.
Three constraints shaped the design:
- Accuracy: Answers had to be grounded exclusively in the source corpus; no hallucination from general model training data. In a compliance context, a wrong answer about GDPR or COPPA requirements carries real risk.
- Cross-topic retrieval: The most valuable queries, like “how does GDPR affect programmatic advertising?”require the system to connect content from multiple source articles simultaneously.
- Maintainability: The corpus needed to be expandable without rebuilding the pipeline. Adding new topics should require nothing more than adding a title to the seed list and re-running the crawler.
Strategic execution
1. Content audit and corpus design
Before building, the knowledge domain was scoped and structured into five topic clusters:
- Core programmatic: Online advertising, demand-side platforms, supply-side platforms, real-time bidding, ad exchanges, header bidding
- Data and audiences: Data management platforms, customer data platforms, lookalike audiences, retargeting, behavioral targeting, contextual advertising
- Metrics and measurement: Cost per mille, click-through rate, conversion tracking, attribution, viewability
- Privacy and regulation: GDPR, CCPA, COPPA, internet privacy, HTTP cookies, third-party cookies, consent management platforms
- Brand safety and fraud: Brand safety, ad fraud, ad blocking
The privacy and regulation cluster was a deliberate inclusion, and not just a technical decision. Privacy regulation is currently the highest-stakes area in programmatic advertising. A knowledge assistant that can answer questions about GDPR compliance or COPPA requirements alongside core AdTech concepts is immediately useful to a real team.
2. Web ingestion via Wikipedia API
Content was ingested using the Wikipedia API rather than HTML scraping. This approach offers three advantages over traditional web crawling:
- No ToS risk: Wikipedia content is Creative Commons licensed; fully permissible for this use case.
- Clean plain text: The API returns pre-extracted plain text with no HTML parsing required.
- Stable content: Wikipedia articles are well-maintained, authoritative, and structurally consistent.
The crawler fetches full article text for each topic in the seed list, normalises whitespace, and saves results to a local JSON file. Total corpus: 24 articles, 68,962 words.
System Architecture
Wikipedia API (24 articles)
↓ fetch
Python Crawler
↓ chunk (800w / 150w overlap)
OpenAI Embeddings
↓ embed (text-embedding-3-small)
Pinecone Vector DB
↓ retrieve (cosine, TOP_K=5)
Flask Query Interface
↓ generate
GPT-4o-mini Response3. Chunking strategy for the programmatic advertising knowledge base
Chunks were set at 800 words with 150-word overlap, which is larger than the 500-word standard used in conversational content pipelines.
The reasoning: AdTech and regulatory articles contain multi-part definitions, numbered lists, and cross-referenced concepts. A 500-word chunk risks splitting a definition from its example, or separating a regulation’s requirements from its enforcement provisions. The 800-word window preserves enough context for coherent retrieval. The 150-word overlap ensures that content near chunk boundaries is captured in at least one retrievable segment.
Ingestion results: 24 articles processed into 120 vectors. Embedding cost: under $0.01.
4. Vector database and retrieval layer
Configured a Pinecone serverless index using cosine similarity and OpenAI’s text-embedding-3-small model (1,536 dimensions). At query time, the user’s question is embedded and matched semantically against the full corpus, retrieving the top 5 most relevant chunks.
Setting TOP_K to 5 rather than the standard 3 was a deliberate decision for this corpus. Cross-topic queries — such as connecting GDPR to programmatic advertising — require chunks from multiple source articles to be retrieved simultaneously. A higher TOP_K increases the probability that both a regulatory article and a programmatic article are present in the context window for the same query.
5. System prompt and generation rules
The system prompt enforces two strict behaviours:
- Answer only from retrieved document context and never from general model training data
- Explicitly acknowledge when information is not present in the knowledge base, rather than guessing
The second rule is critical for a regulatory compliance use case. A system that confidently fabricates a GDPR requirement is more dangerous than one that says, “I don’t have that information.”
6. Deployment
Deployed as a Flask web application on Render. The chat interface includes four suggested starter questions to demonstrate the system’s range from core AdTech concepts to cross-topic regulatory queries.
System performance
| Metric | Result |
|---|---|
| Articles indexed | 24 |
| Vectors stored | 120 |
| Topic clusters | 5 |
| Total words indexed | 68,962 |
| Embedding cost | < $0.01 |
| Estimated monthly running cost | ~$20–40 (OpenAI API + Render free tier) |
Stress test results
Cross-topic retrieval
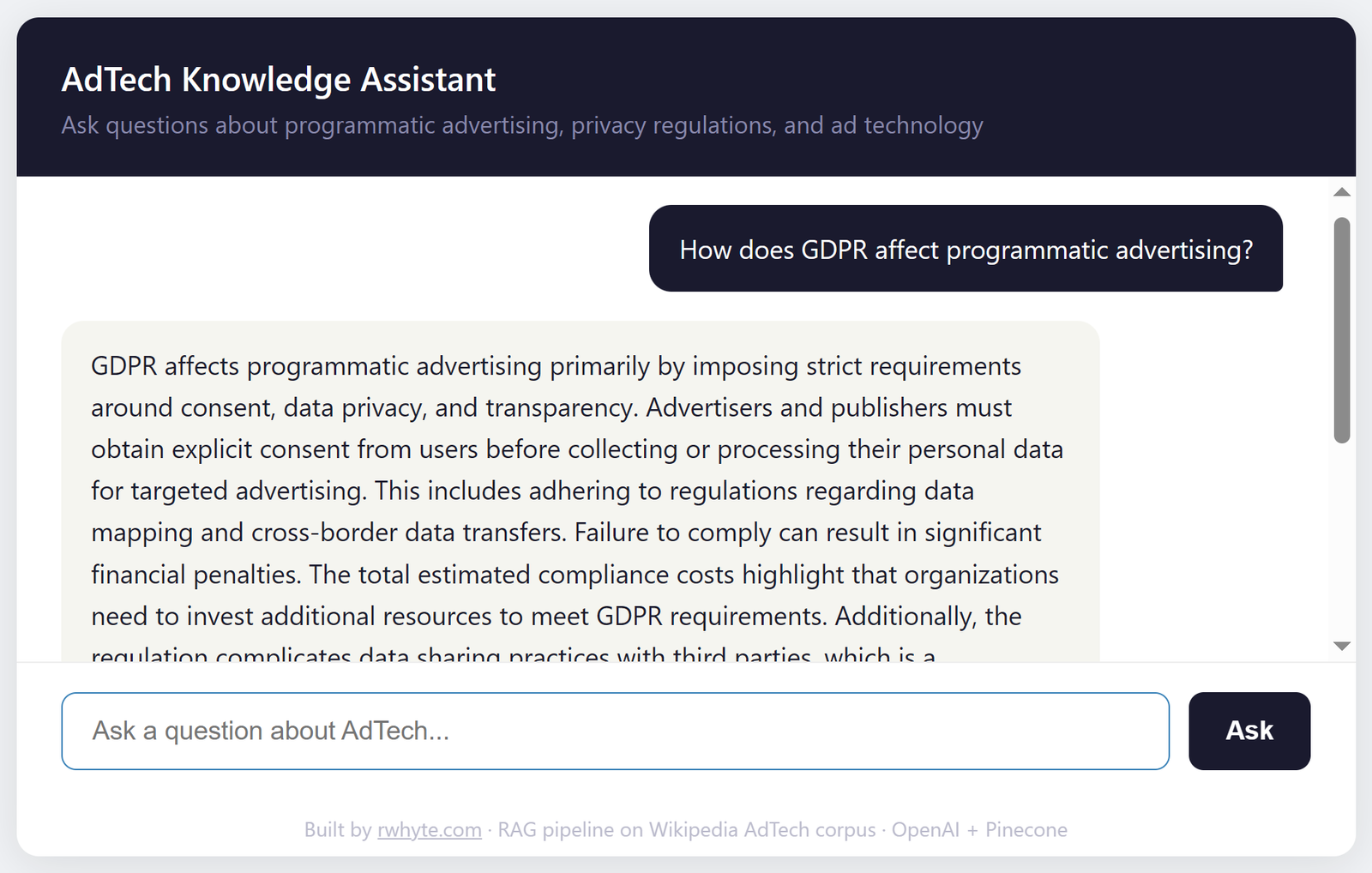
“How does GDPR affect programmatic advertising?”
Answer: The General Data Protection Regulation (GDPR) significantly impacts programmatic advertising by imposing strict requirements on data privacy, consent, and security. Advertisers must obtain explicit consent from users before collecting or processing personal data. Non-compliance can result in severe financial penalties. GDPR has also influenced user behaviour, increasing privacy-conscious practices and ad blocker usage, which impacts how programmatic campaigns are executed and measured.
This response required retrieval across the GDPR article and the Online Advertising article simultaneously — the single most valuable capability for a team navigating regulatory compliance.
Comparative concept retrieval
“What is the difference between a DSP and an SSP?”
Answer: A DSP automates the buying of ad impressions for advertisers, managing campaigns by target audience, bid amounts, and budgets. An SSP helps publishers manage and sell advertising inventory, connecting with DSPs and ad exchanges to maximise revenue. DSPs target advertisers; SSPs target publishers.
Hallucination test
“What is the CPM rate for a Toyota campaign on Google?”
Answer: I don’t have information on that in my knowledge base.
Pricing data is not in the corpus. The system correctly declined to answer rather than generating a plausible-sounding fabrication.
Interpretation
This project demonstrates that a Python-based RAG pipeline built on web-crawled content can deliver production-quality knowledge retrieval at near-zero ingestion cost.
The key design decisions — Wikipedia as a clean, permissible source; 800-word chunks to preserve regulatory context; TOP_K of 5 to enable cross-topic retrieval; strict grounding rules in the system prompt — are knowledge architecture decisions, not engineering decisions. They determine whether the system is accurate and trustworthy over time.
The corpus is fully expandable. Adding new topics requires one line in the seed list and a re-index run. The intellectual assets — topic taxonomy, chunking strategy, grounding rules — are reusable across any domain.
Resources
- Live demo (suggested questions: What is the difference between a DSP and an SSP? / How does GDPR affect programmatic advertising?)
- GitHub repository